这些方法代表了一个统一体的两端。词袋方法是最简单的方法,其中甚至忽略了基本的语法构造。自然语言处理则是另一个极端,其中计算机从本质上理解词、词之间的关系以及它们在现实世界中表示的概念。
少数词袋方法的扩展使其变得更加有用。其中大多数可以实现自动化,而在过去——开发一个词典则不行。
1.停用词
停用词(stop words)是指没有意义的词。在这种情况下,意义是指区分不同文档的能力。例如,几乎所有的英文文档都包含词“the”,而对于典型的文本挖掘应用程序——诸如分类、派生变量、导航等等——而言,这个词实际上毫无意义。
停用词列表可以从Web上发现、手动构造,甚至自动构件。在最后一种情况下,会搜索整个语料库中出现的词,不考虑与文档的任何关系。尽管停用词往往是常见的单词(比如of、through和and),但是不太常见的例子包括nevertheless、differently和furthering等。
2.词根化
词根化(Stemming)是把单词缩减为它们的“词干”的过程,而词干是指基本词或提供意思且不附带额外语法信息的准词(almost-word)。例如,单词“stemming”将被转换成单词“stem”,单词“stems”和“stemmed”同样如此。
词根化的目的是为了更好地获取文档的内容。一位客户的投诉可能会提到“延迟交付(late delivery)”,而另一位客户可能会说“不按时交付(not delivered on time)”,这两个短语没有任何共同的词。使用词根化之后,它们会拥有共同的词“deliver”。
3.词对和短语
确定词对(Word pair)和短语(phrase)对于理解文本往往非常重要。摇滚乐队“The Who”是一个著名的自动文本处理的例子。大多数停用词列表都包括the和who,所以这个短语将从文档中完全消失。这可能会很有问题。
这个问题有两种解释方案。简单的解决方案是保持大写的停用词,或者至少是不在句首的大写停用词。一个更加复杂的解决方案是查找常见的词对和短语,并确保保留它们。
4.使用词典
大多数文本挖掘的业务应用程序会涉及一种或另一种形式的词典(lexicon)。词典是一个重要单词的列表。它还可能包括同义词,因此几个不同的词可能会被合并到一个单一的概念,其中包括错误拼写。例如,“flight”、“fl”和“flt”在航空评论中都可能表示“flight(航班)”。
构建词典往往是文本挖掘中最费时的部分。词典的部分内容是针对整个行业。然而,每家公司都有自己的语言,专业用来描述它的产品、市场和优惠等等。这种语言也应该是词典的一部分。
关于TeamDoc软件:
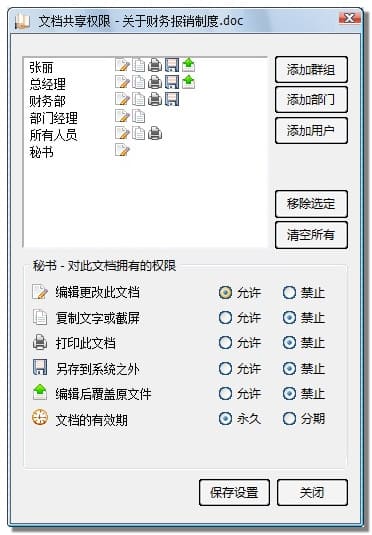
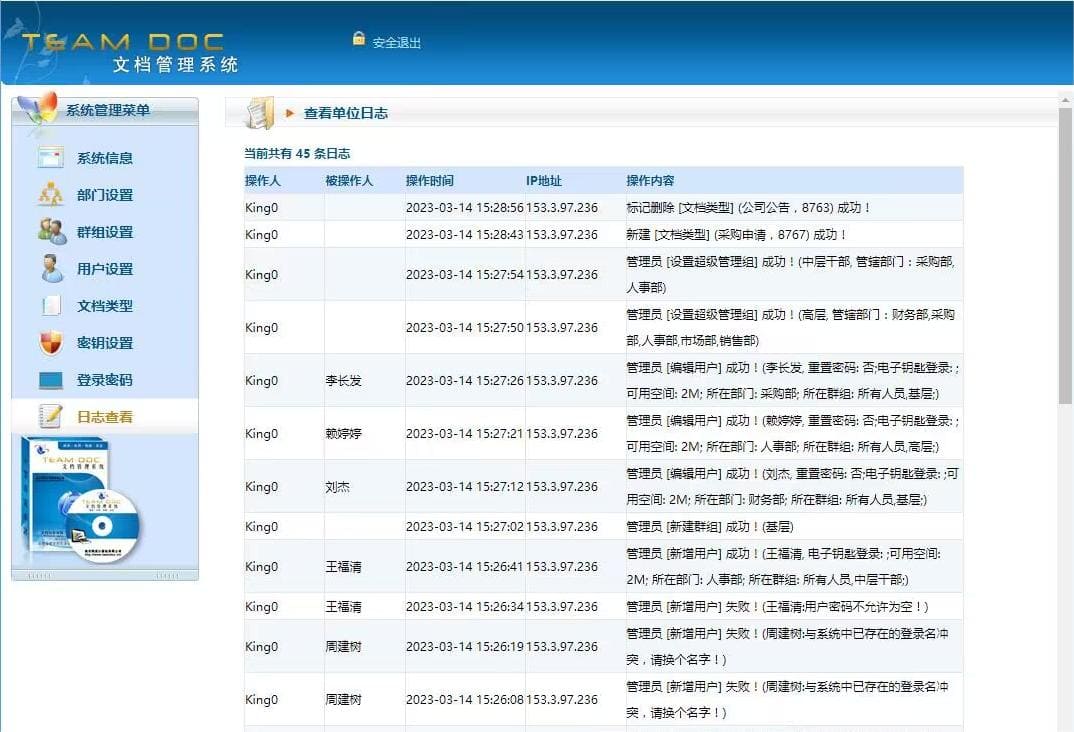
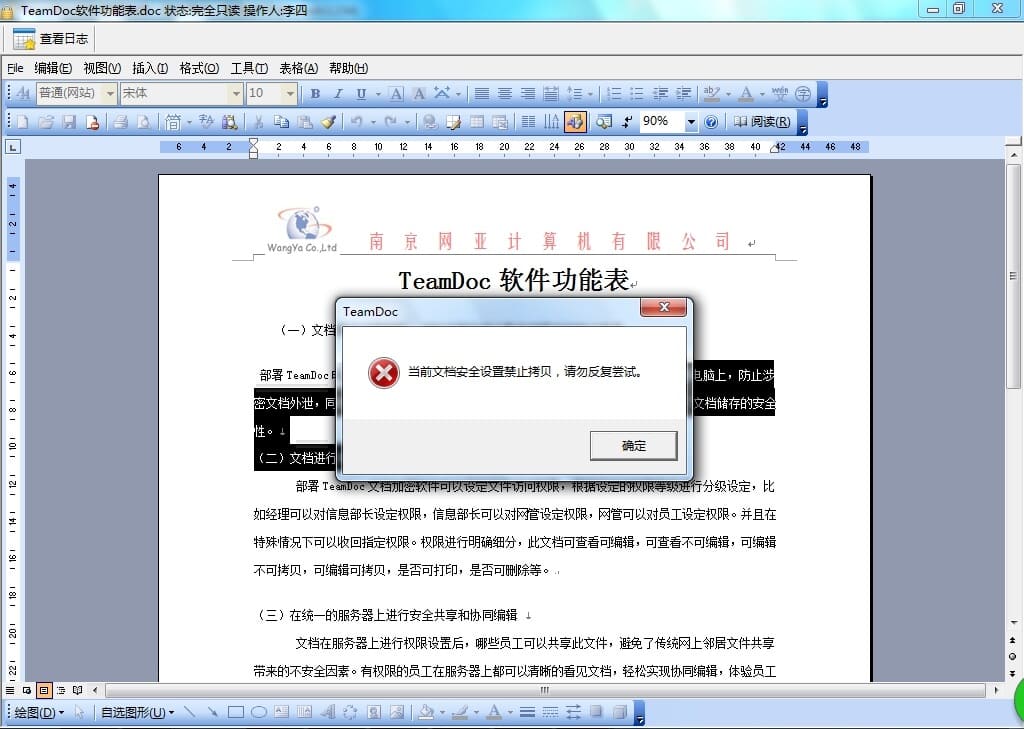
TeamDoc是基于服务器/客户端架构的轻量级文件管理软件。TeamDoc将文件集中加密存储在您单位自己的服务器中,员工使用TeamDoc客户端访问服务器,从而获得与自己权限相关的权限:登入后与“我的电脑”界面类似,可以看到自己该看的文件,编辑自己能编辑的文档,对于能看到的文件,还可以细分文档权限,进而做到能看不能拷,能看不能截屏等功能,多种权限灵活设置,在线协同编辑、全文搜索、日志与版本追踪,快速构建企业文档库。告别假大空,我们提供值得您选择的、易用的、可用的文档管理软件。现在就访问TeamDoc首页
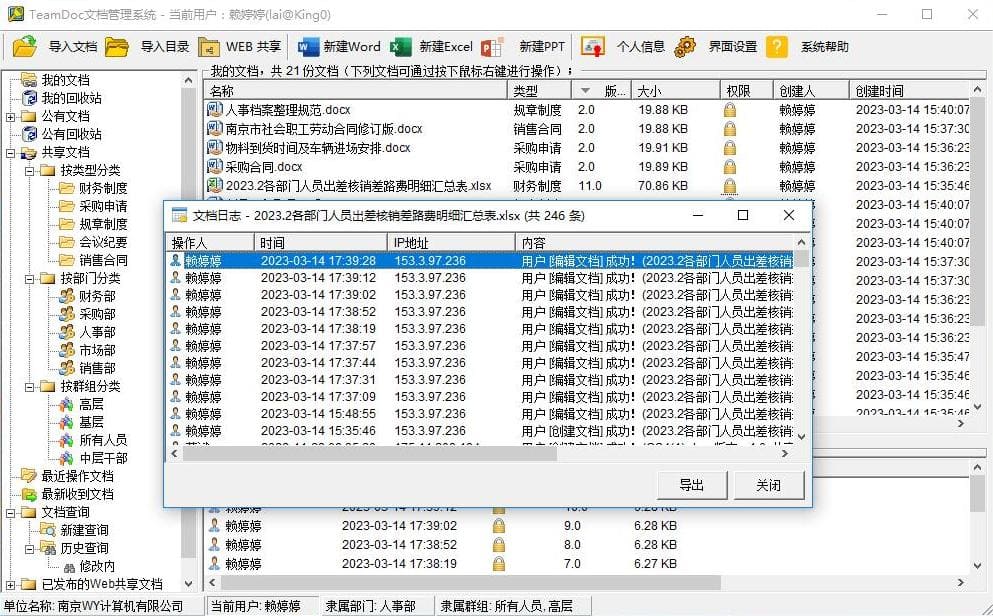
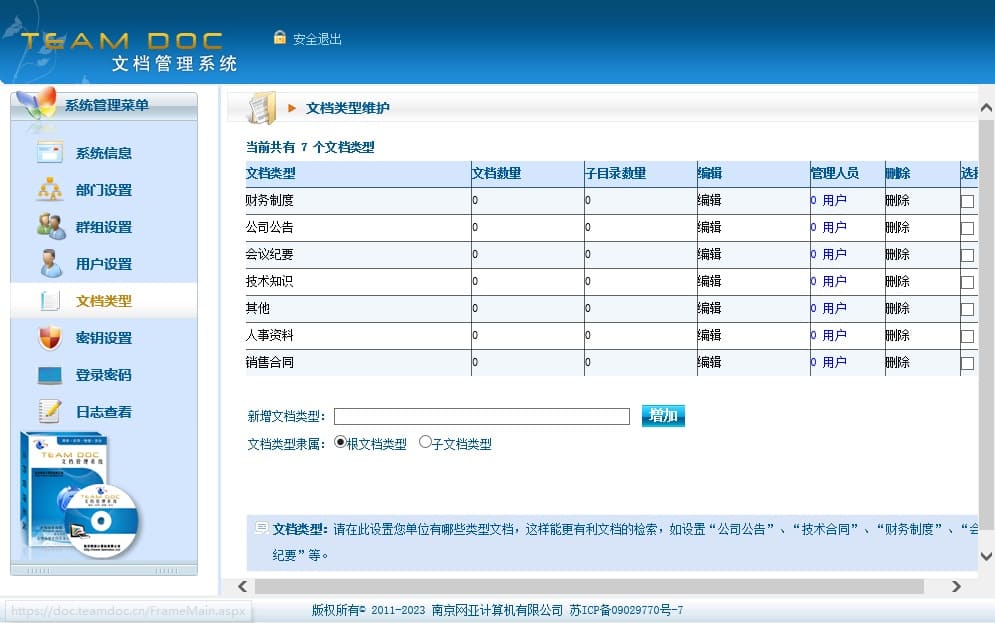
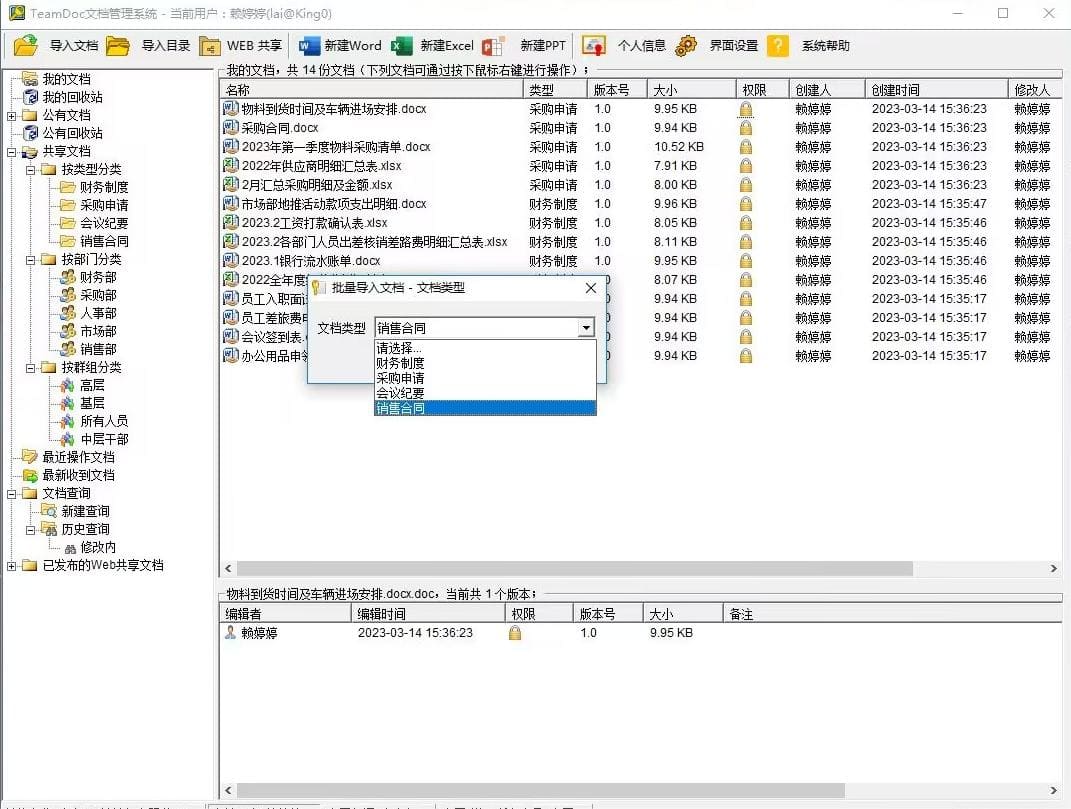
TeamDoc软件界面(点击可放大)


版权所有:南京网亚计算机有限公司,本文链接地址: 实践中的文档表示