企业文档管理系统是企业信息化建设的重要组成部分,它可以帮助企业更好地管理和利用各种文档信息。在企业文档管理系统中,模拟退火算法可以应用于优化文档检索和分类等方面。
一个具体的例子是如何使用模拟退火算法来优化文档分类。在企业文档管理系统中,通常需要将各种文档进行分类,以便更好地管理和利用这些文档。然而,文档分类的过程比较繁琐,需要耗费大量的时间和人力。如果能够使用模拟退火算法来优化文档分类的过程,将可以大大提高分类的准确性和效率。
我们可以将每个文档表示为一个向量,其中每个维度表示一个特征。例如,我们可以使用文档的标题、正文、作者等作为特征。然后,我们可以使用聚类算法将这些向量分成不同的簇。但是,聚类算法通常需要选择合适的簇数和初始中心点,这些参数的选择可能会影响聚类结果的准确性。
因此,我们可以使用模拟退火算法来优化聚类算法的参数选择,以达到最优的聚类效果。具体来说,我们可以将聚类算法的参数选择看作是一个决策变量,然后使用模拟退火算法来搜索最优的参数组合。在每个迭代步骤中,我们可以计算当前参数组合下的聚类效果,并将其作为能量函数来评估当前解的优劣。然后,我们通过一定的概率接受新解,或者保留当前解。

通过多次迭代,模拟退火算法最终会收敛到一个最优解。这个最优解给出了一个最佳的聚类算法参数选择,可以实现最优的文档分类效果。
以下是使用模拟退火算法实现文档聚类的 Python 代码例子:
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
# 生成一些随机数据用于测试
X, _ = make_blobs(n_samples=100, centers=3, n_features=10, random_state=42)
# 定义能量函数(即聚类误差)
def energy_function(X, kmeans):
return kmeans.inertia_
# 定义模拟退火算法
def simulated_annealing(X, n_clusters, max_iter=10000, temp=1.0, alpha=0.99):
# 初始化聚类算法
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
kmeans.fit(X)
# 初始化当前解和能量值
current_solution = kmeans
current_energy = energy_function(X, kmeans)
# 初始化最优解和能量值
best_solution = current_solution
best_energy = current_energy
# 迭代优化
for i in range(max_iter):
# 随机生成一个新解
new_solution = KMeans(n_clusters=n_clusters, random_state=42)
new_solution.cluster_centers_ = current_solution
.cluster_centers_ + np.random.normal(scale=1.0, size=(n_clusters, X.shape[1]))
# 计算新解的能量值
new_energy = energy_function(X, new_solution)
# 如果新解更优,则接受它
if new_energy < current_energy:
current_solution = new_solution
current_energy = new_energy
# 否则,以一定概率接受新解
else:
delta_energy = new_energy - current_energy
prob = np.exp(-delta_energy / temp)
if np.random.uniform() < prob:
current_solution = new_solution
current_energy = new_energy
# 更新最优解
if current_energy < best_energy:
best_solution = current_solution
best_energy = current_energy
# 降低温度temp *= alpha
return best_solution
# 测试
n_clusters = 3
solution = simulated_annealing(X, n_clusters)
labels = solution.labels_
print(labels)
以上代码使用 make_blobs 函数生成一些随机数据,然后使用 KMeans 算法进行聚类。然后,定义能量函数为聚类误差,即 KMeans 算法的 inertia_ 属性。最后,使用模拟退火算法来优化 KMeans 算法的聚类结果。在每个迭代步骤中,随机生成一个新的聚类中心,并计算新的聚类误差。如果新的聚类误差更小,则接受新的聚类中心;否则以一定概率接受新的聚类中心。通过多次迭代,最终得到一个最优的聚类结果。
关于TeamDoc软件:
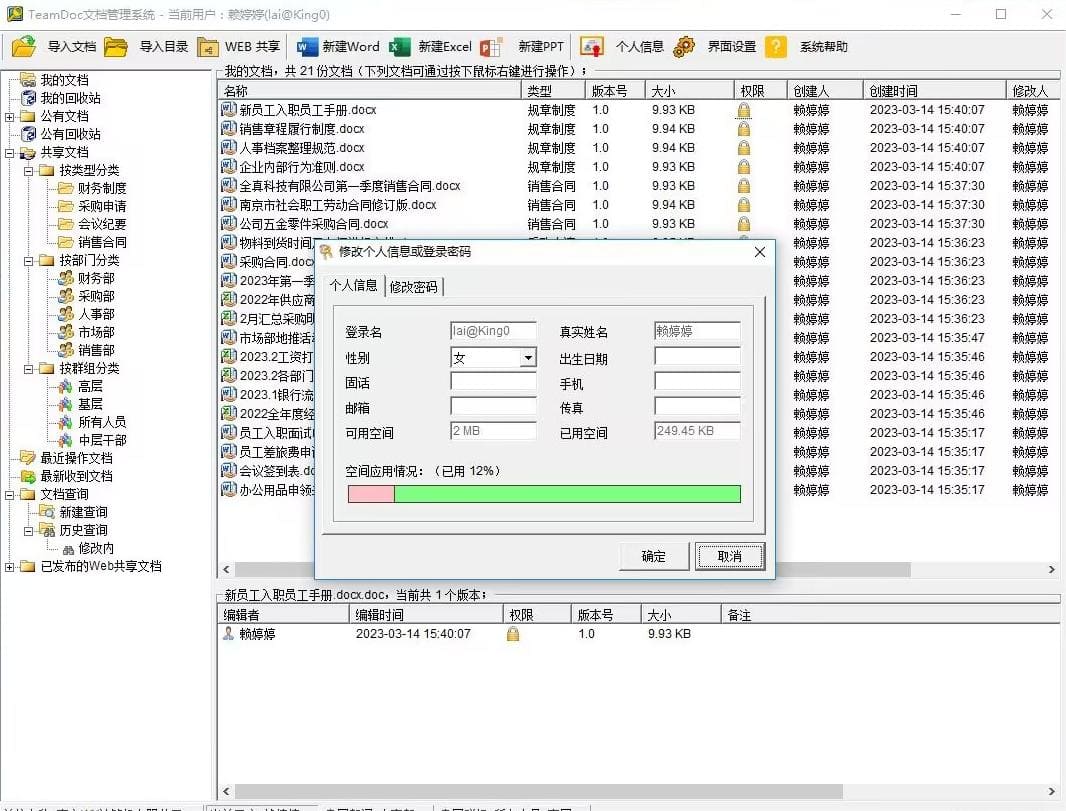
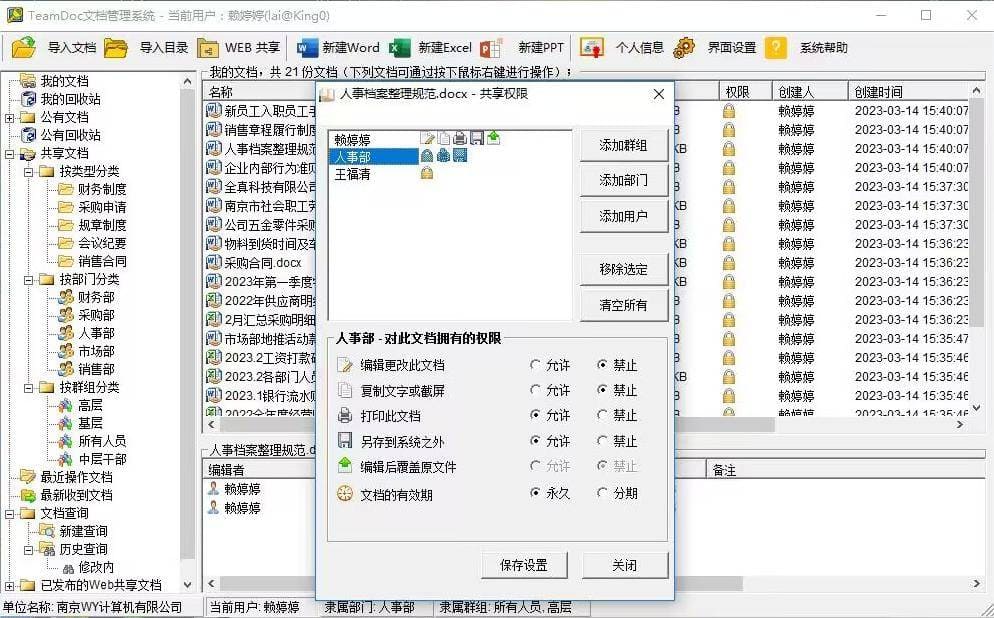
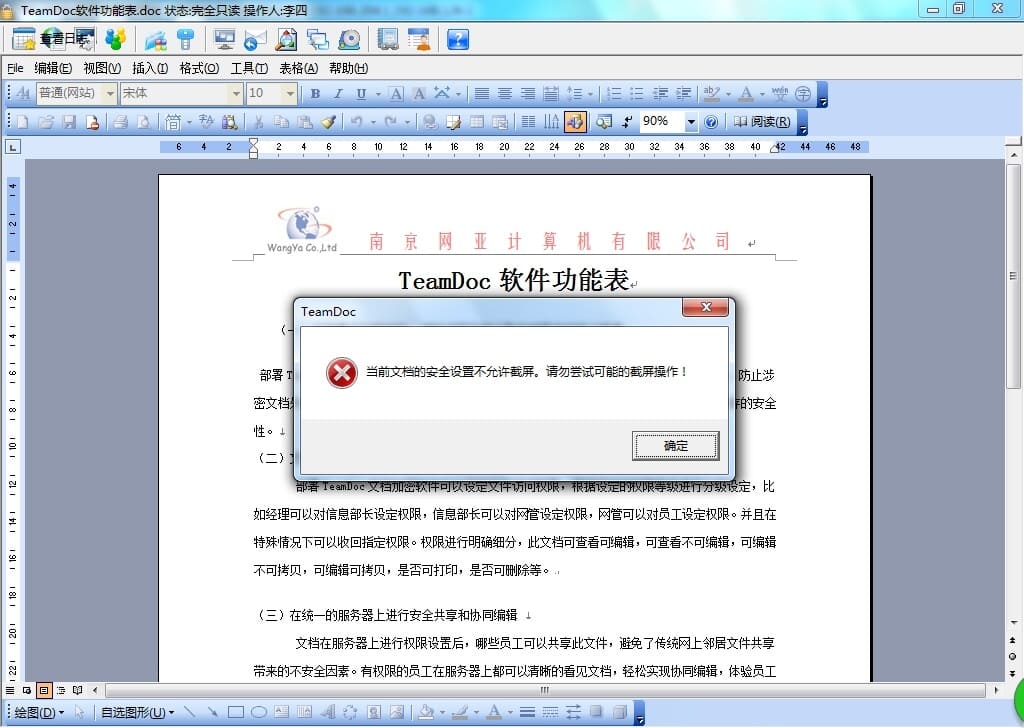
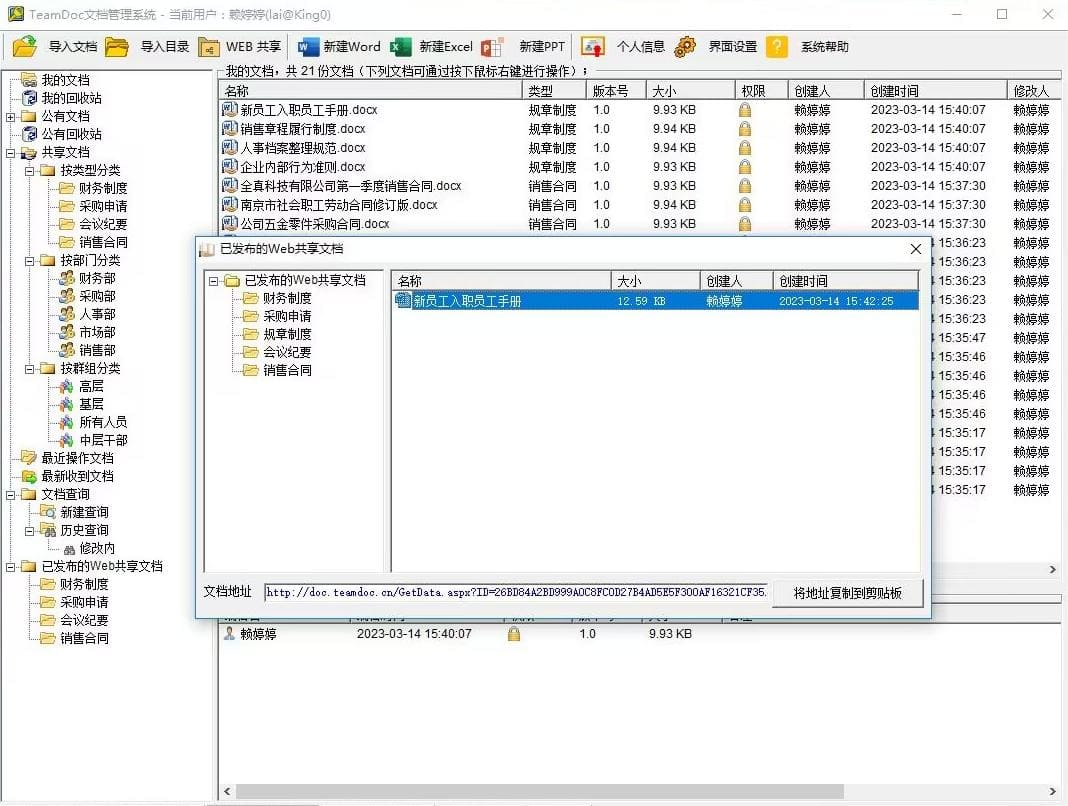
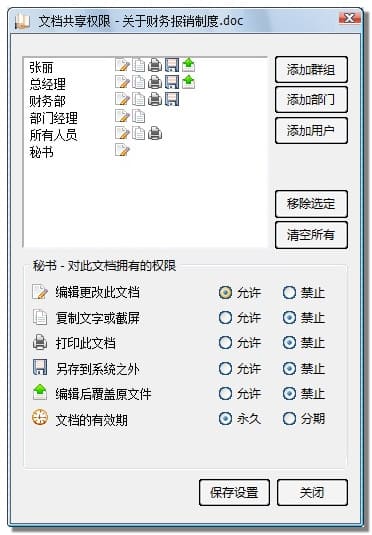
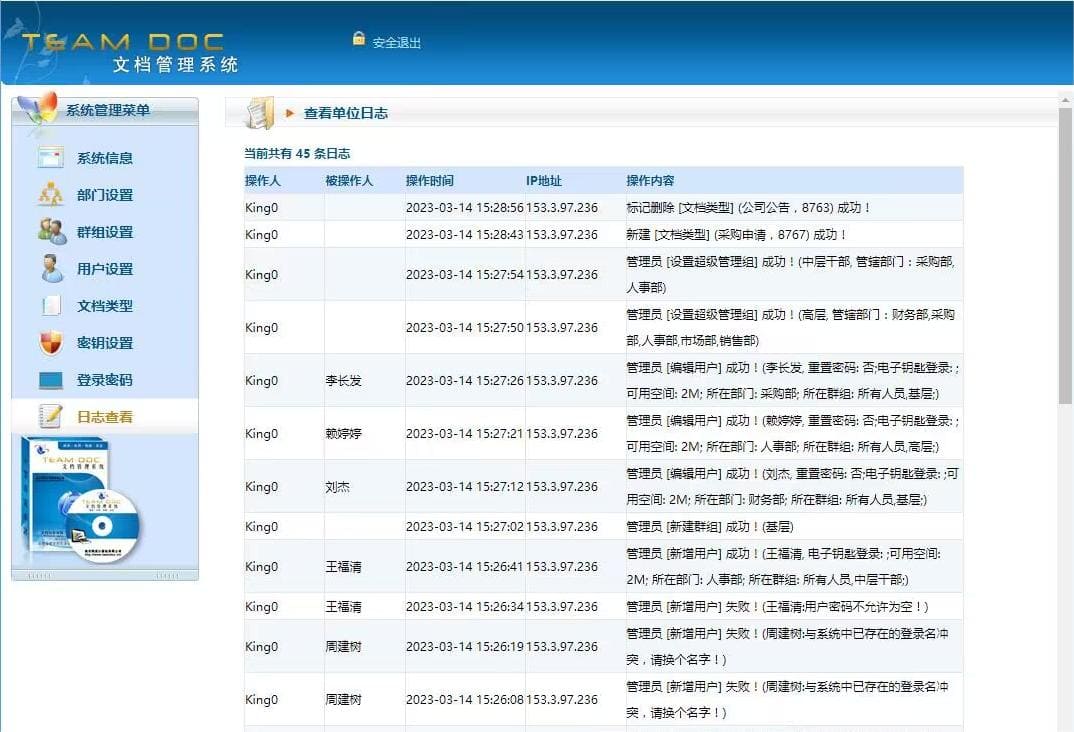
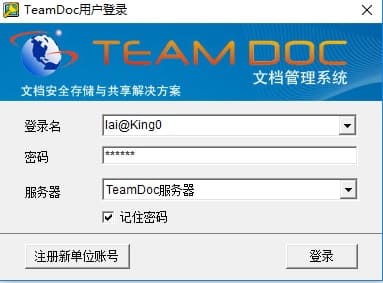
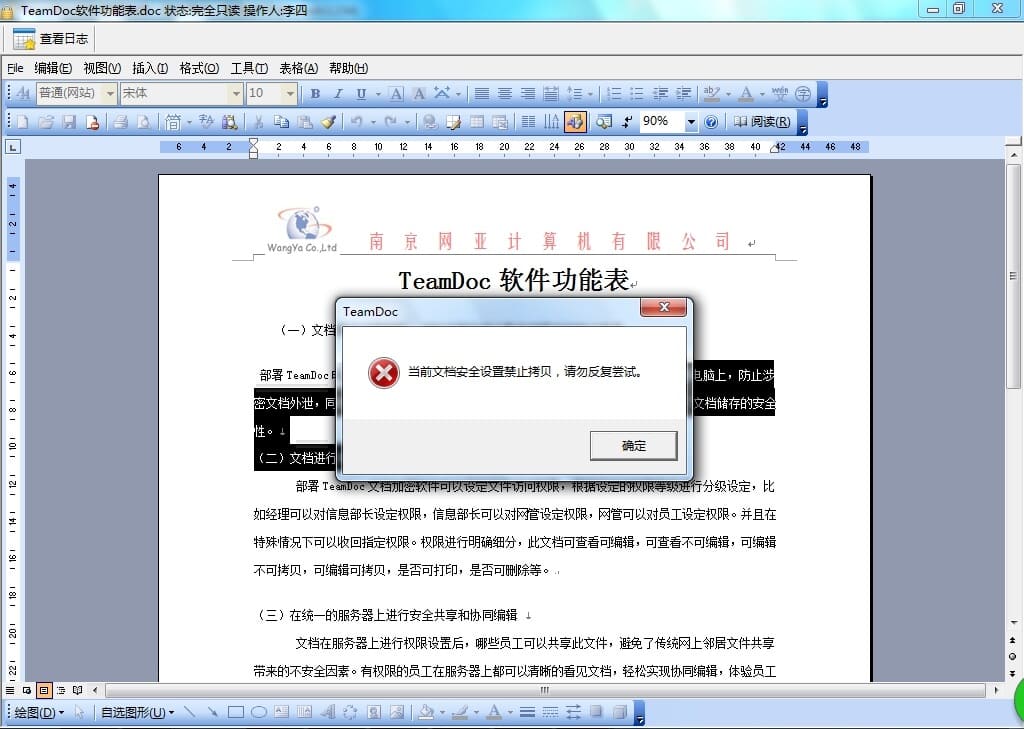
TeamDoc是基于服务器/客户端架构的轻量级文件管理软件。TeamDoc将文件集中加密存储在您单位自己的服务器中,员工使用TeamDoc客户端访问服务器,从而获得与自己权限相关的权限:登入后与“我的电脑”界面类似,可以看到自己该看的文件,编辑自己能编辑的文档,对于能看到的文件,还可以细分文档权限,进而做到能看不能拷,能看不能截屏等功能,多种权限灵活设置,在线协同编辑、全文搜索、日志与版本追踪,快速构建企业文档库。告别假大空,我们提供值得您选择的、易用的、可用的文档管理软件。现在就访问TeamDoc首页
TeamDoc软件界面(点击可放大)


版权所有:南京网亚计算机有限公司,本文链接地址: 模拟退火算法在企业文档管理系统中的代码示例