模式识别(Pattern Recognition)是一门关于从观察到的数据中提取有用信息、建立抽象模型以解释观察数据的科学。模式识别算法是模式识别的基础技术,是从大量的观察数据中识别出相关模式、判别相似性和决策的方法。
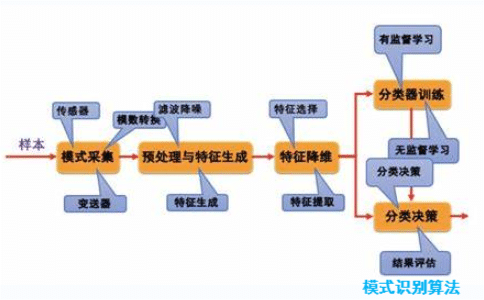
- 分类(Classification):根据给定的训练数据集,通过一定的算法将新的未知数据对象分为离散的类别。常见的分类算法有:KNN,决策树,随机森林,支持向量机,朴素贝叶斯,神经网络等。
- 聚类(Clustering):将数据对象分为若干组,每组数据对象具有相似性。常见的聚类算法有:K-means,DBSCAN,层次聚类等。
- 回归(Regression):预测与一个或多个自变量有关的因变量的值。常见的回归算法有:线性回归,多项式回归,岭回归,Lasso回归等。
- 特征提取(Feature Extraction):从原始数据中提取出对识别任务有意义的特征,使得后续的识别更加容易和高效。常见的特征提取算法有:PCA。
模式识别算法是一种数据分析方法,用于将数据分类到一组预先定义的类别中。模式识别算法通常用于图像识别、语音识别、手写字符识别等应用领域。常用的模式识别算法包括:
- k-NN(k-Nearest Neighbors)
- 决策树
- 朴素贝叶斯
- 支持向量机
- 神经网络
- 聚类算法
模式识别算法的性能由数据质量和选择的算法决定。因此,在使用模式识别算法之前,通常需要对数据进行清理、预处理和归一化,以提高识别精度。
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
X = np.array([[0, 0], [1, 1]]) # Training data
y = np.array([0, 1]) # Labels for training data
knn = KNeighborsClassifier(n_neighbors=1) # Create a k-NN classifier
knn.fit(X, y) # Train the classifier
test_data = np.array([[2, 2]]) # Test data
prediction = knn.predict(test_data) # Predict class for test data
print("Prediction:", prediction)
In this example, X and y represent the training data and its corresponding labels. The KNeighborsClassifier class is used to create a k-NN classifier, which is then trained on the training data using the fit method. Finally, the classifier is used to make a prediction on a test data point.
关于TeamDoc软件:
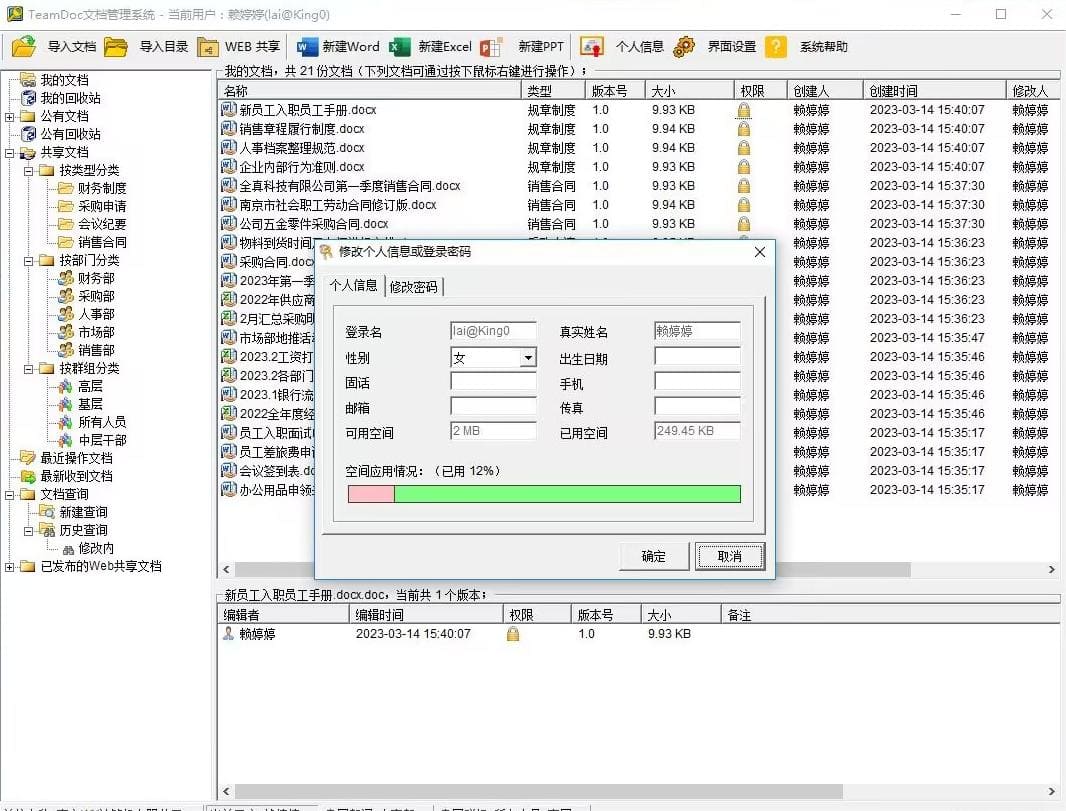
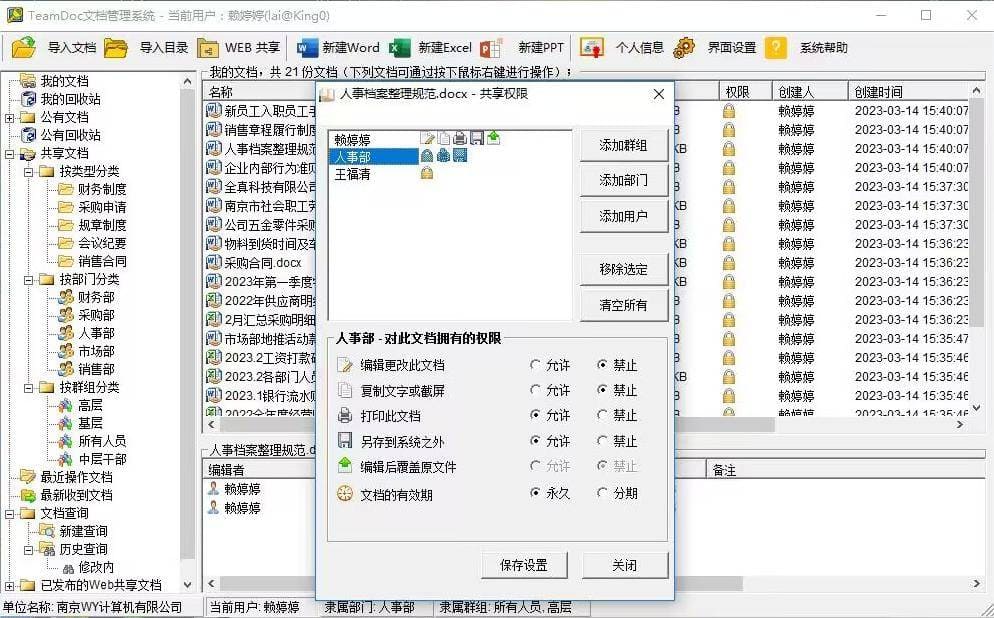
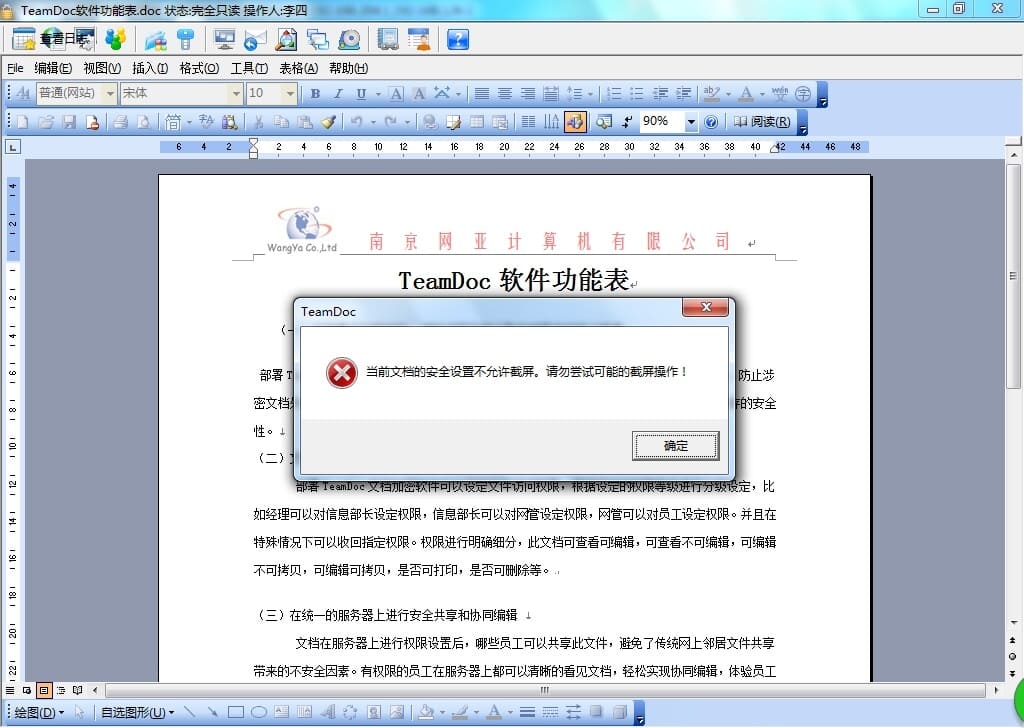
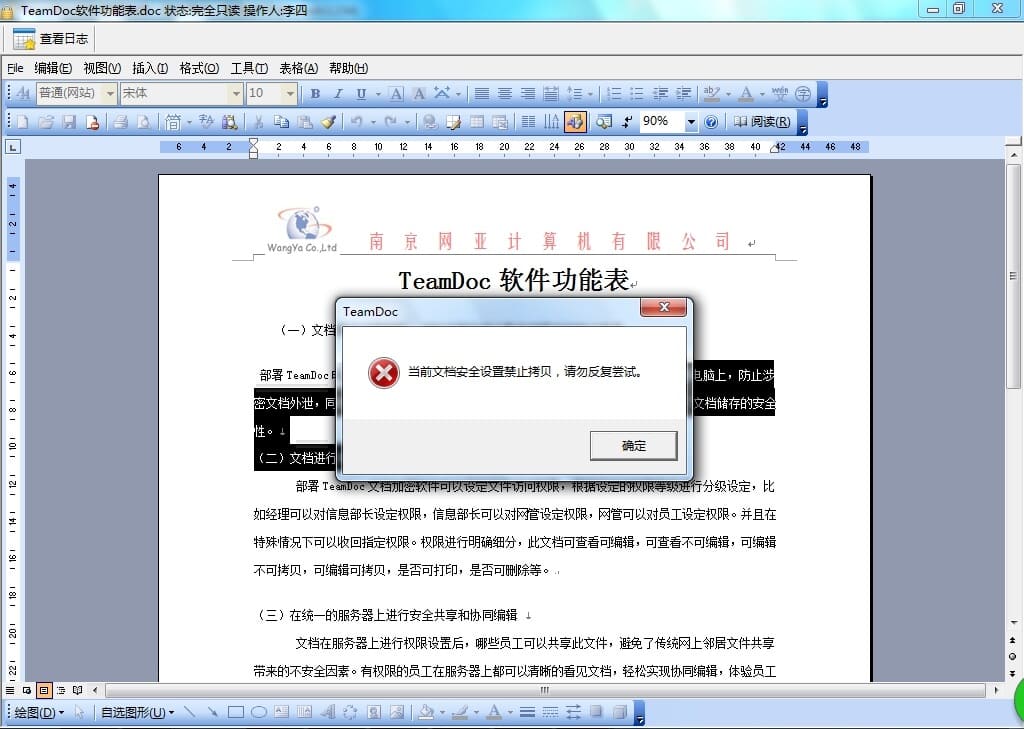
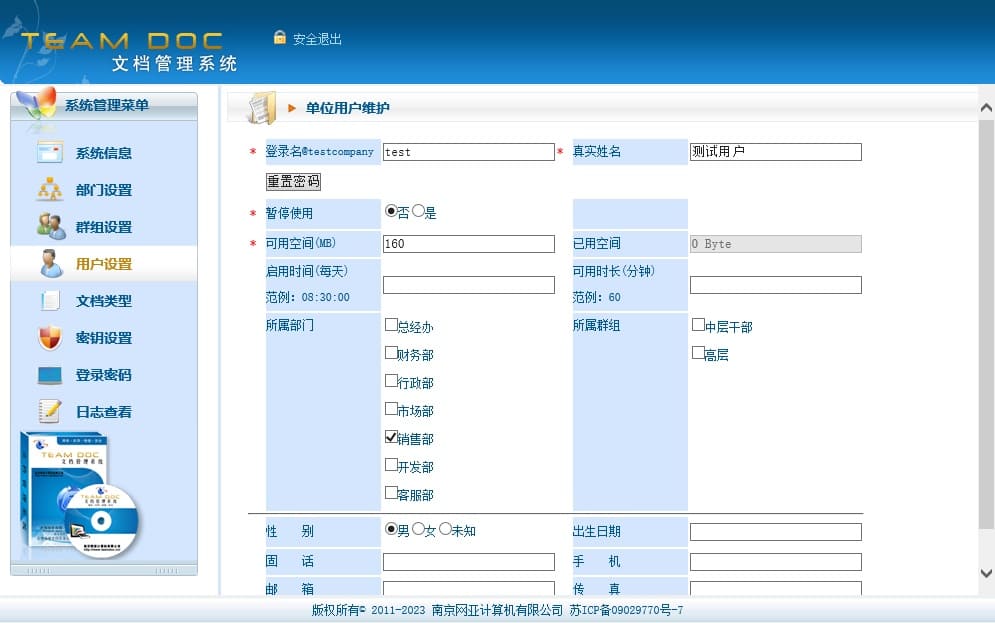
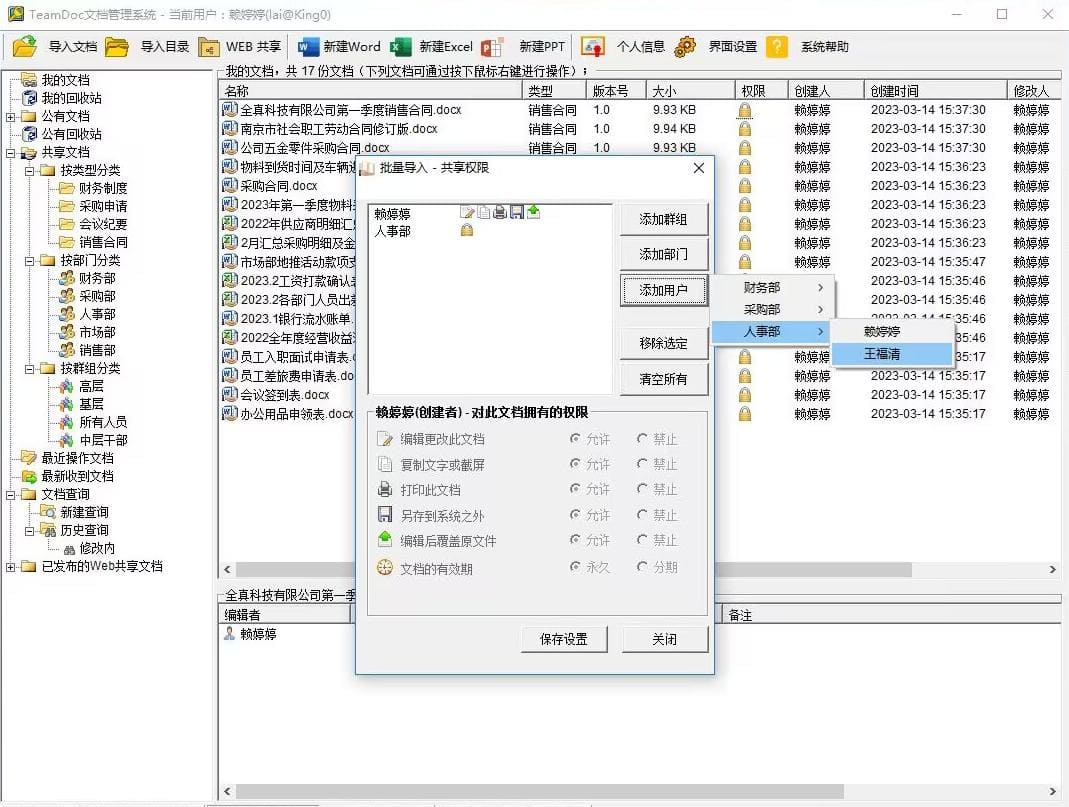
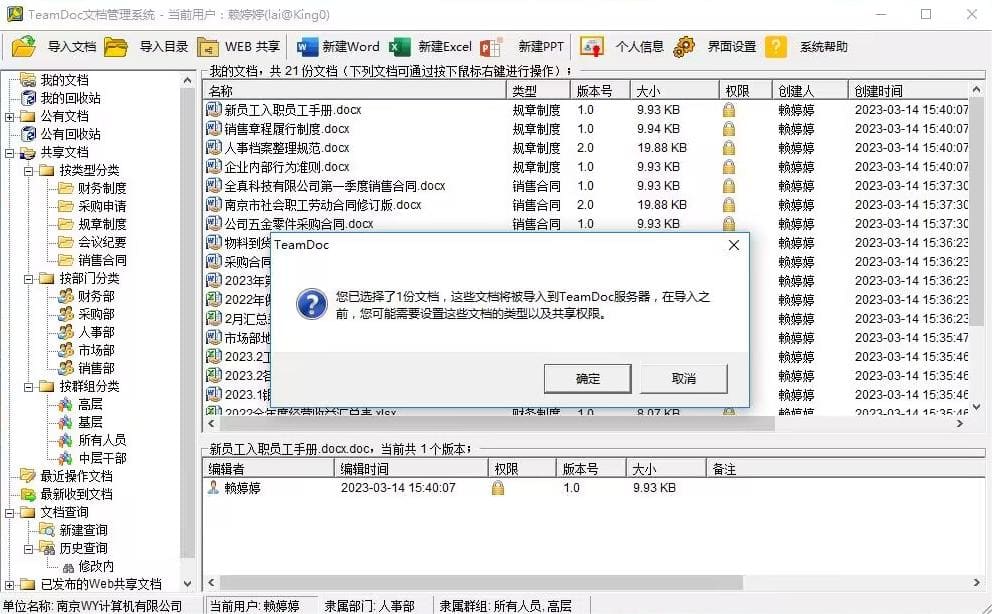
TeamDoc是基于服务器/客户端架构的轻量级文件管理软件。TeamDoc将文件集中加密存储在您单位自己的服务器中,员工使用TeamDoc客户端访问服务器,从而获得与自己权限相关的权限:登入后与“我的电脑”界面类似,可以看到自己该看的文件,编辑自己能编辑的文档,对于能看到的文件,还可以细分文档权限,进而做到能看不能拷,能看不能截屏等功能,多种权限灵活设置,在线协同编辑、全文搜索、日志与版本追踪,快速构建企业文档库。告别假大空,我们提供值得您选择的、易用的、可用的文档管理软件。现在就访问TeamDoc首页
TeamDoc软件界面(点击可放大)


版权所有:南京网亚计算机有限公司,本文链接地址: 模式识别算法档案