它使用HiveQL,是Hadoop上最早的类SQL DSL之一。这只是一个面向SQL的DSL实例,使得MapReduce对非程序员更易于使用。Hive是HDFS上一个类SQL的查出工具,它支持用户为数据定义带有schema的表,并编写内部使用MapReduce实现的查询。Hive并不是一个关系数据库系统,因为它没有事务和记录级别CRUD的概念。但它确实提供了一种易于文件管理数据库用户理解的语言。它将重点放在查询上——对数据发问,并进行聚合。
尽管新的Hadoop用户可能倾向于将Hive用作关系数据库,但必须知道HiveQL命令被翻译成了MapReduce批量作业。这导致Hive不适合需要快速完成的查询。Hive从未打算取代企业文件管理数据仓库,而是作为一种简化数据集处理的方法,它使得要处理数据集、从文件管理数据获得价值的人不再必须是一名Java开发者。
Hive使用一个外部DSL。HiveQL有自己的语法、编译器和运行时程序。多数Hive查询是以MapReduce作业实现的,但用于创建和修改数据库、表和视图的数据定义语言语句并不需要MapReduce。Hive将这些元数据信息保存在独立的关系数据库中。多数查询会触发一个或多个MapReduce作业,并通过Hive对不同数据格式的插件支持来读取和处理HDFS或其他数据存储中的文件管理数据。
关于TeamDoc软件:
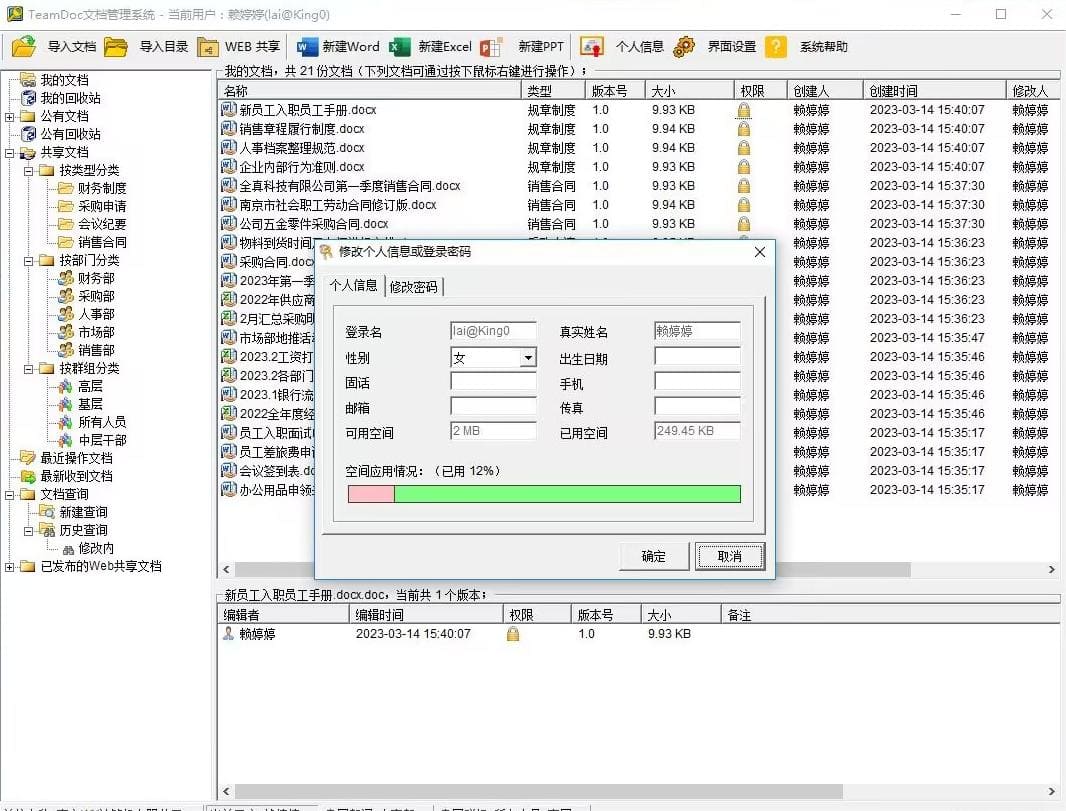
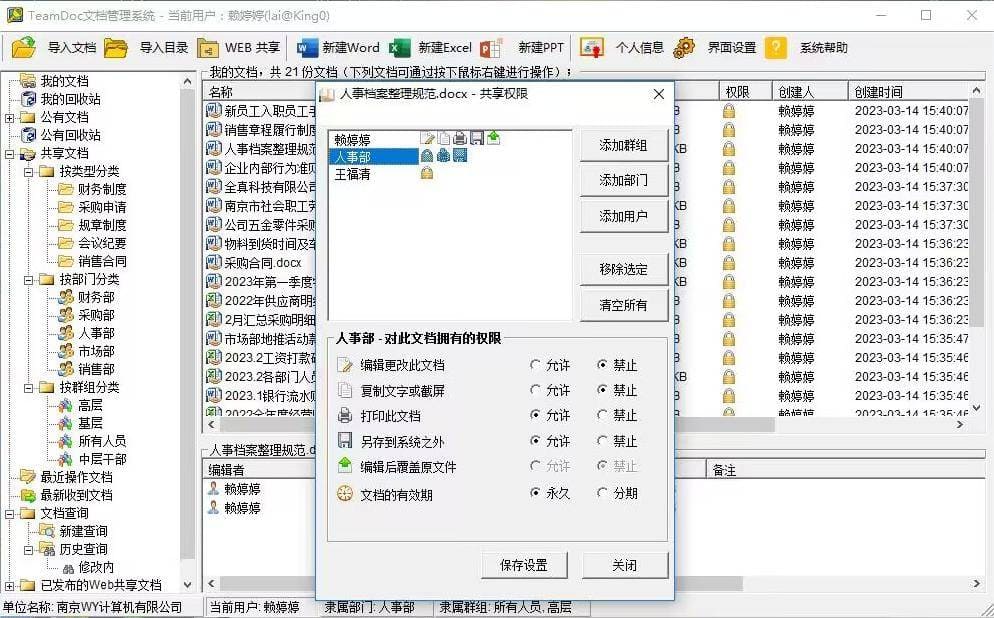
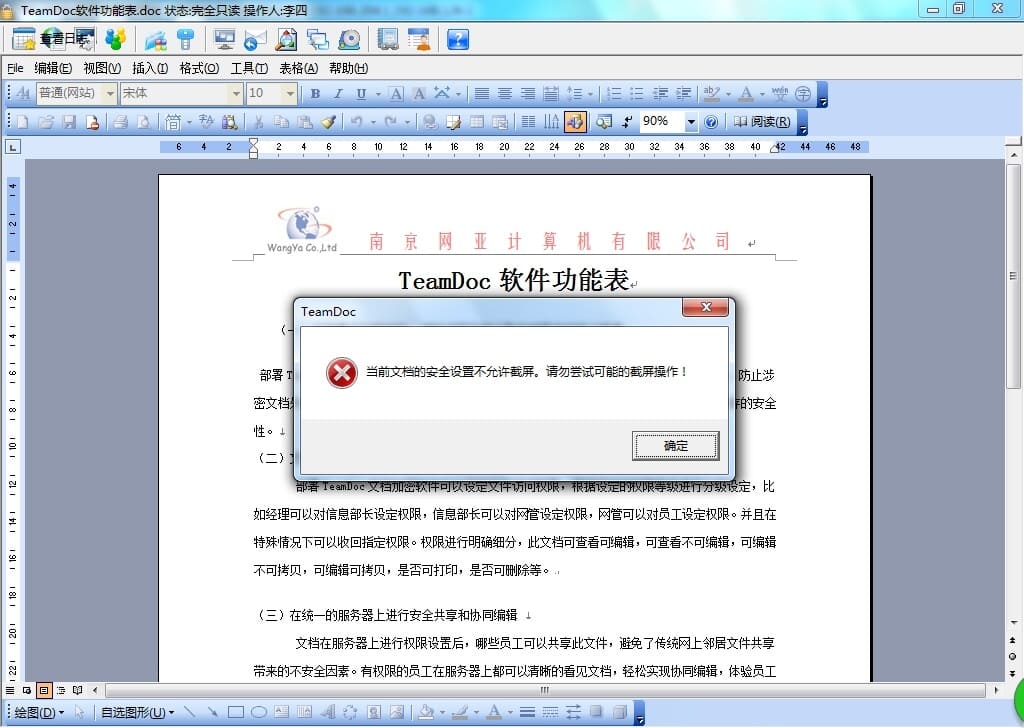
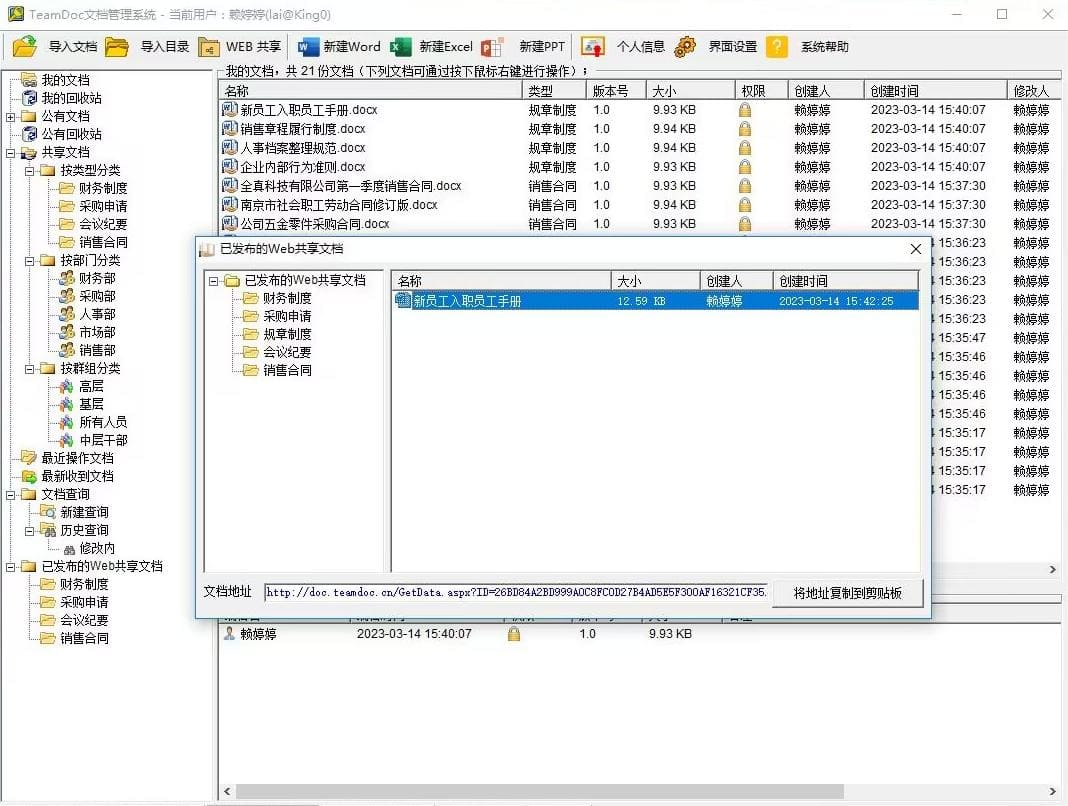
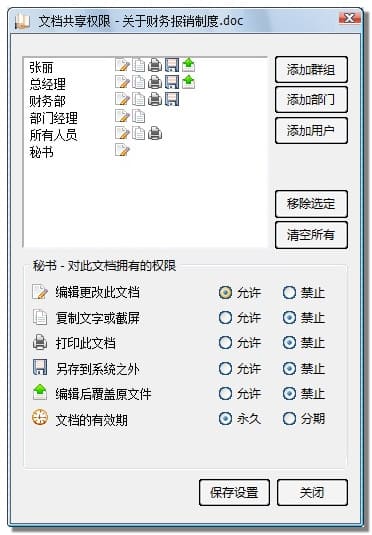
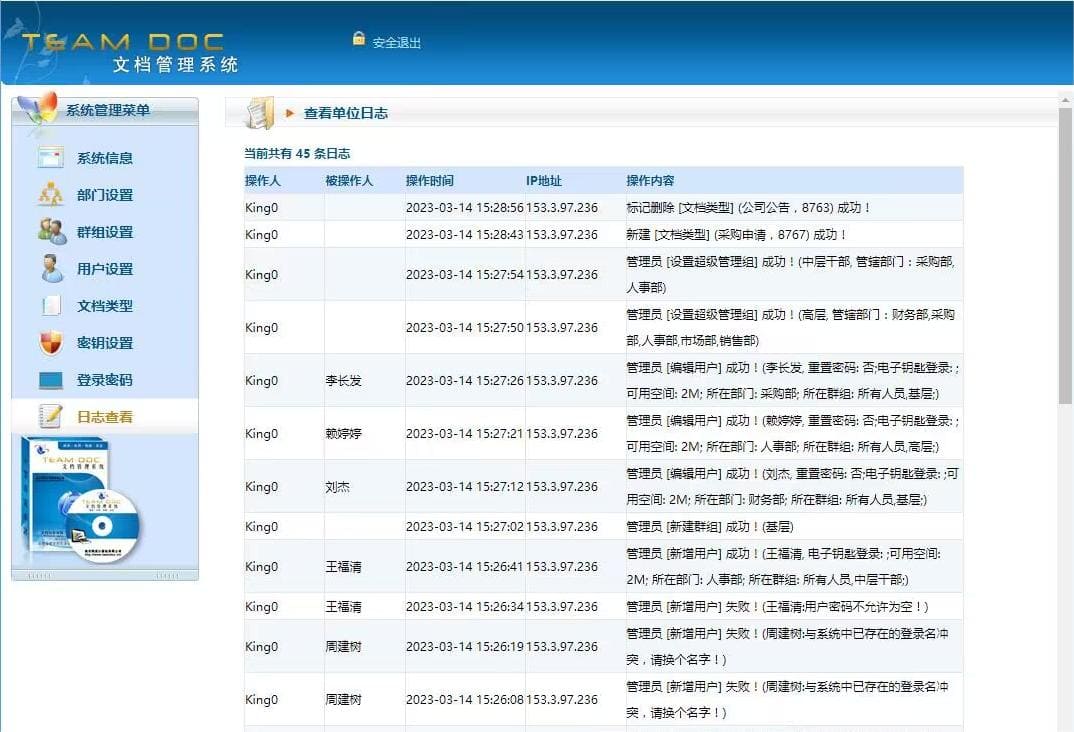
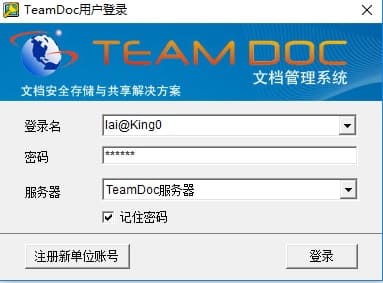
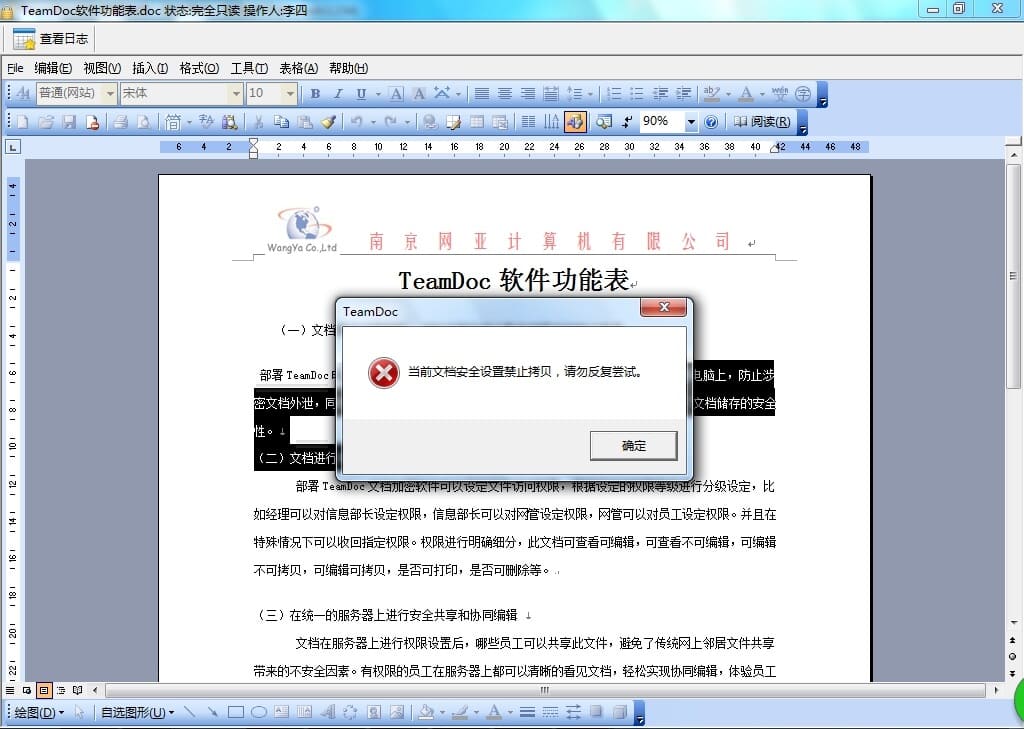
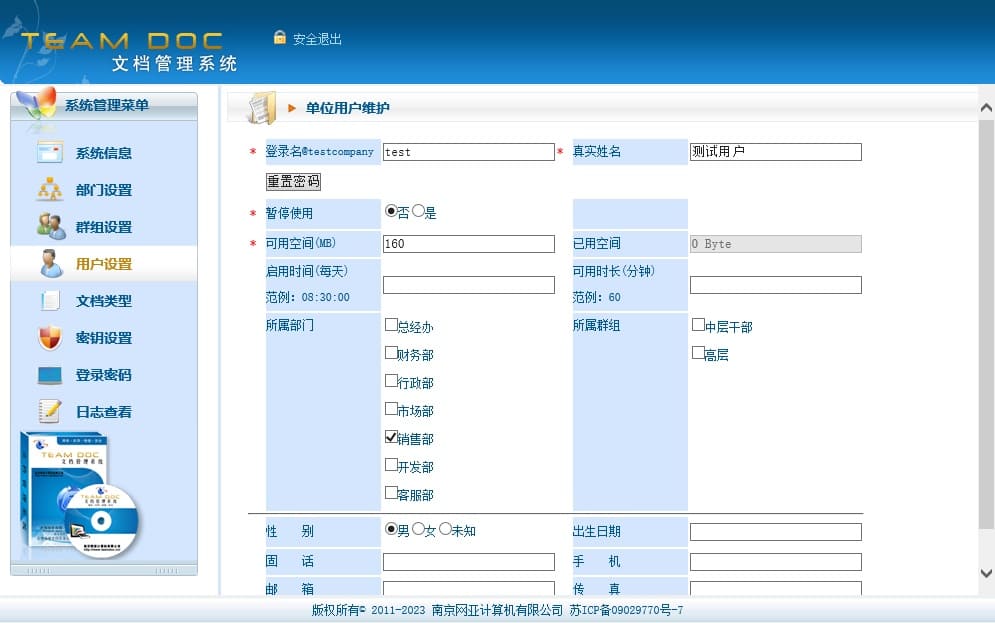
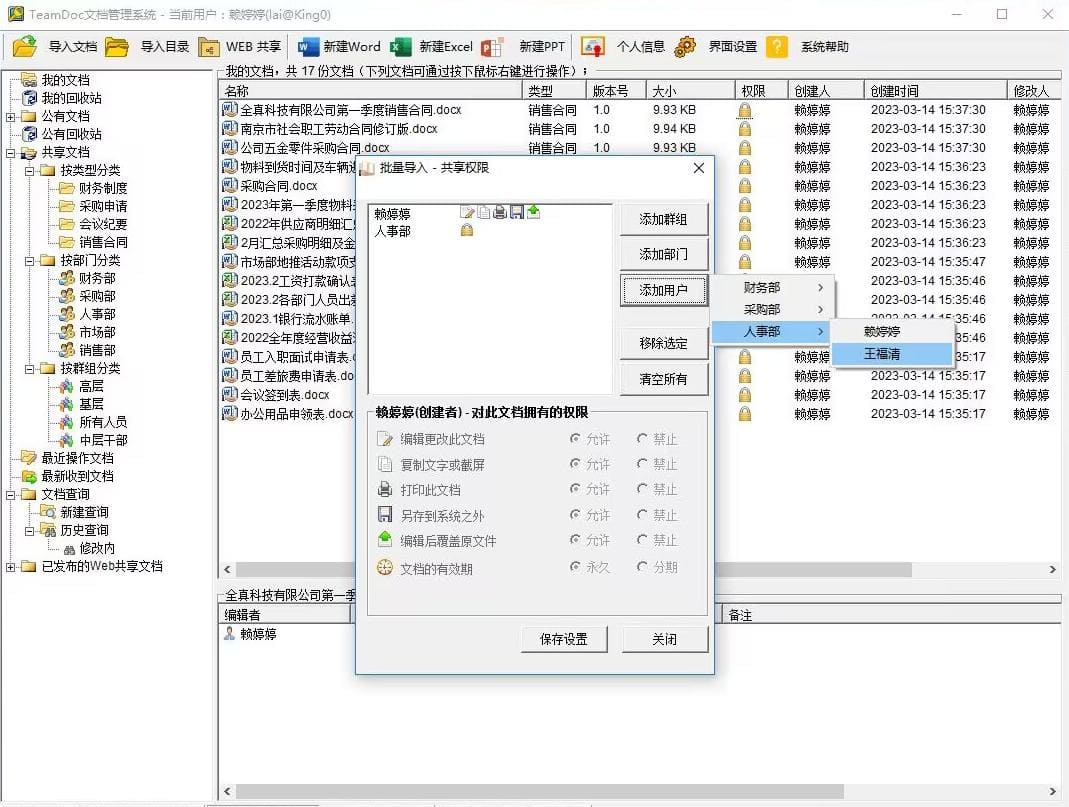
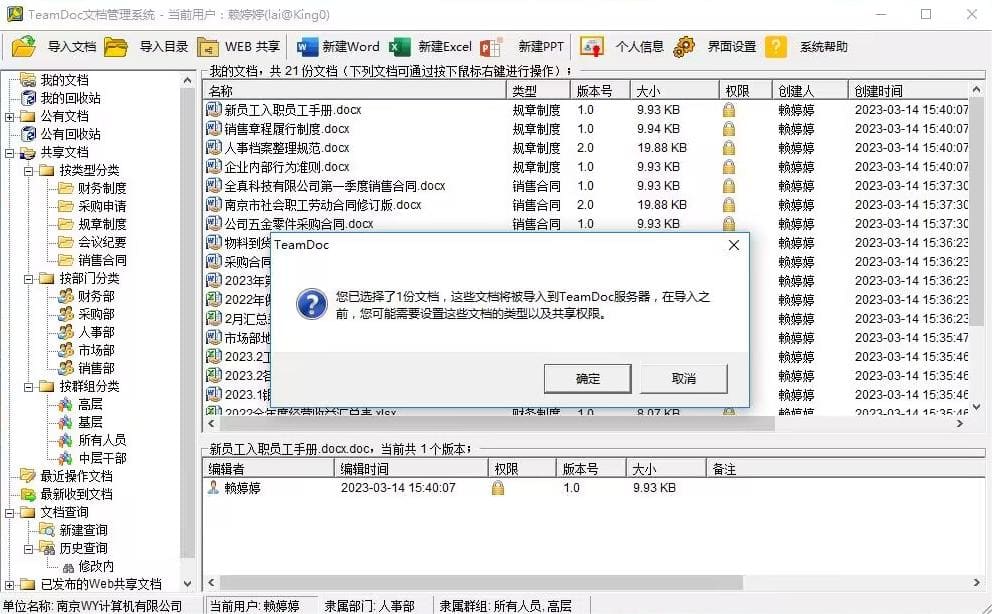
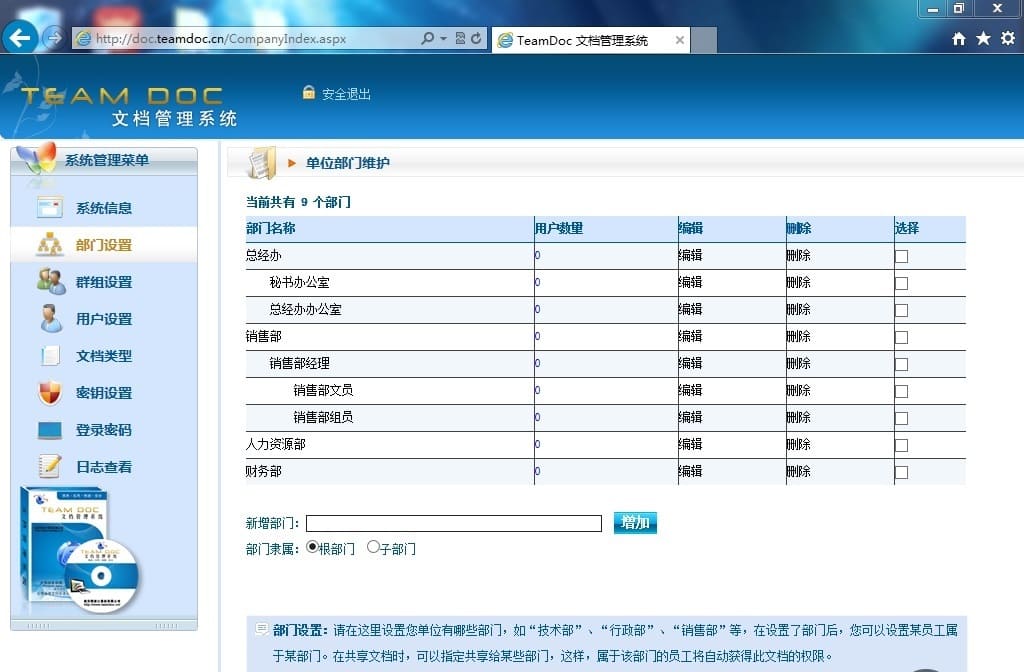
TeamDoc是基于服务器/客户端架构的轻量级文件管理软件。TeamDoc将文件集中加密存储在您单位自己的服务器中,员工使用TeamDoc客户端访问服务器,从而获得与自己权限相关的权限:登入后与“我的电脑”界面类似,可以看到自己该看的文件,编辑自己能编辑的文档,对于能看到的文件,还可以细分文档权限,进而做到能看不能拷,能看不能截屏等功能,多种权限灵活设置,在线协同编辑、全文搜索、日志与版本追踪,快速构建企业文档库。告别假大空,我们提供值得您选择的、易用的、可用的文档管理软件。现在就访问TeamDoc首页
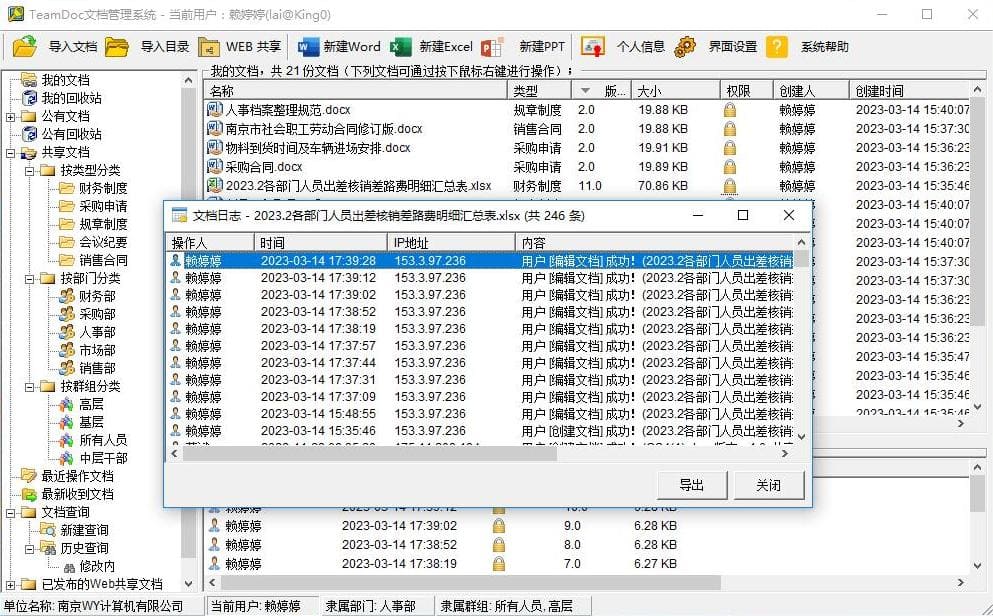
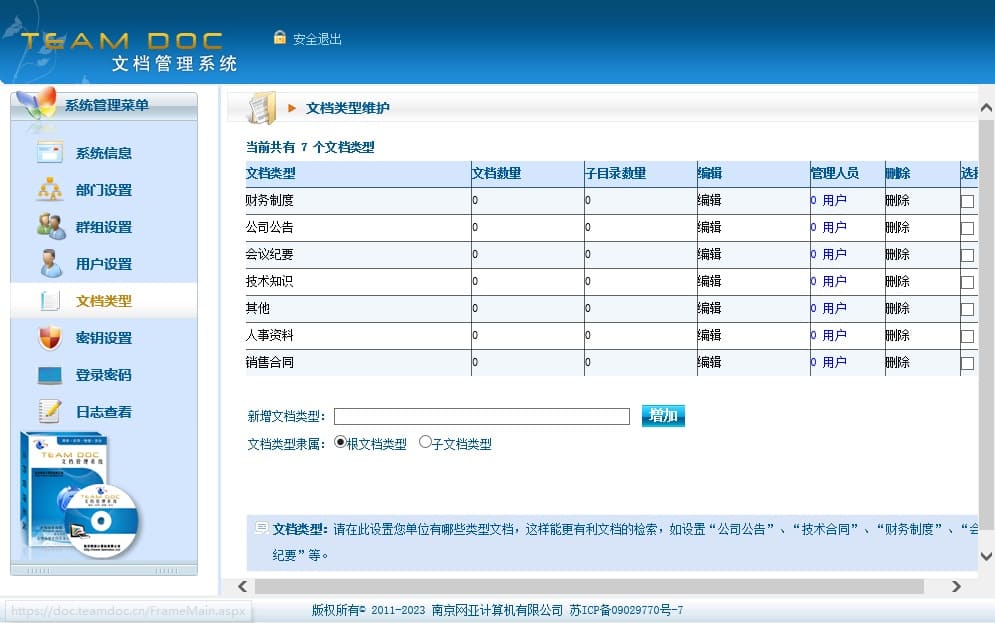
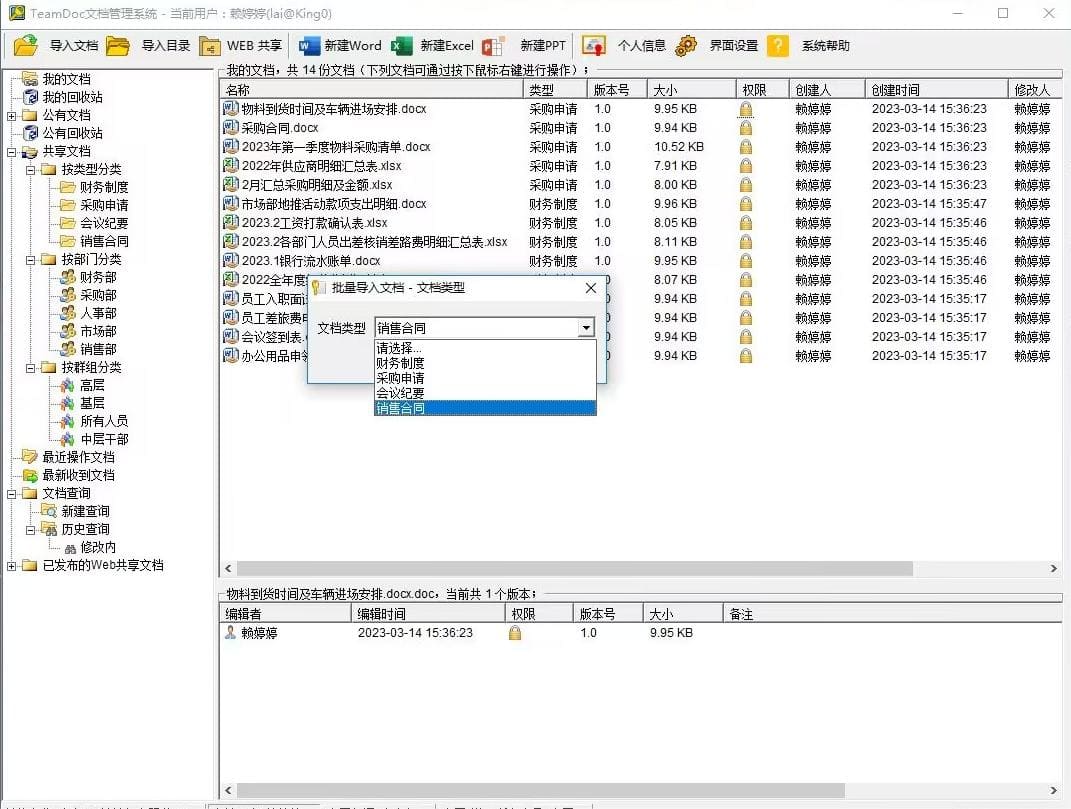
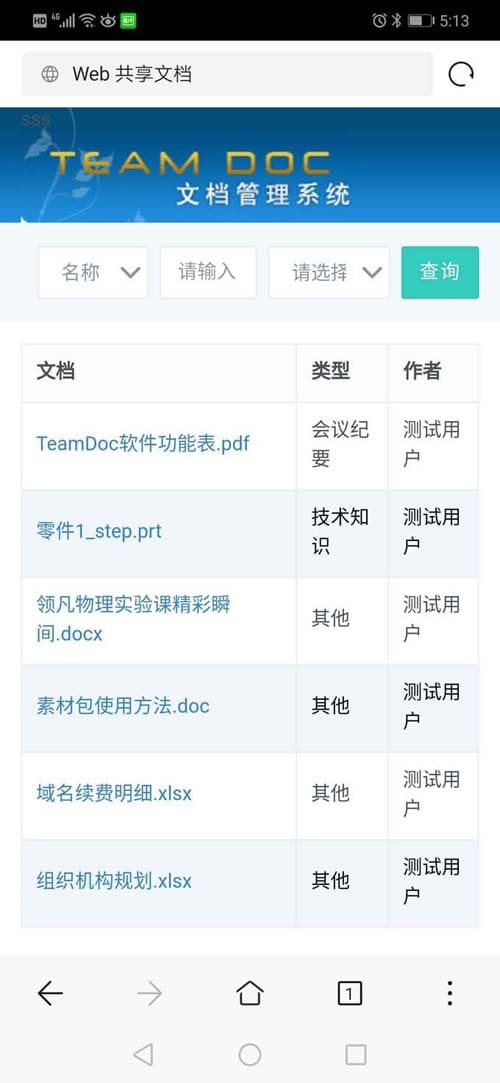
TeamDoc软件界面(点击可放大)


版权所有:南京网亚计算机有限公司,本文链接地址: Hive和基于文件管理数据SQL的DSL